RAG 구현 기록
2026년 05월 02일
늘 여러 가지 핑계로 미뤄왔던 것들을 조금씩 정리해보고자 합니다.
이번 글은 시리즈 형태가 될 수도 있을 것 같은데, 직전 회사에서 RAG 기반 아키텍처를 구성했던 경험을 기록해보려고 합니다.
평소에도 정리해두어야겠다고 생각했던 내용이었고, 인터뷰 과정에서 자주 언급되었던 부분이기도 해 이 기회에 정리하게 되었습니다.
먼저 최종 구현 했던 기술 아키텍처 구조는 아래와 같습니다.
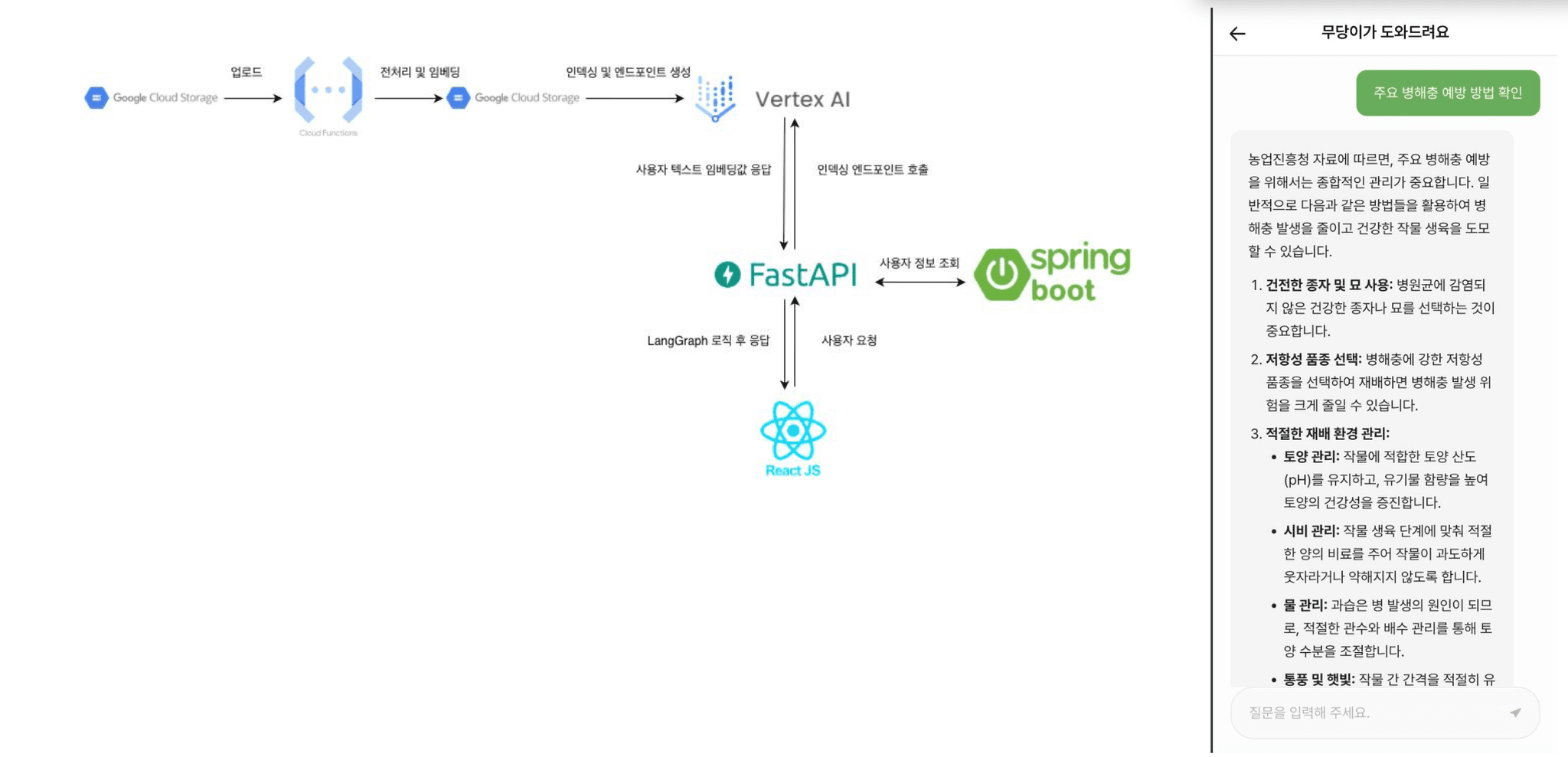
1. RAG가 필요했던 이유
이야기를 시작하기에 앞서, 당시 개발했던 서비스에 대해 간단히 설명드리겠습니다.
당시 회사에서는 스마트팜 플랫폼을 준비하고 있었으며, 영농일지를 제대로 활용하지 못했던 기존 농부들과 농사를 처음 시작하는 초보 농부들을 대상으로
농장 기반의 추천 할 일과 데이터 관리 기능을 제공하는 서비스를 기획했습니다.
내부 기획 회의 끝에 나온 핵심 기능은 아래와 같았습니다.
- LLM을 활용한 추천 할 일 제시
- 농장 데이터에 대한 빠른 조회 및 질의응답
이미 Google Gemini API를 활용한 PoC를 진행했고, 해외 박람회에서 긍정적인 피드백을 받은 상태였기 때문에 이를 실제 서비스 수준으로 발전시킬 필요가 있었습니다.
다만 단순히 LLM을 붙이는 방식으로는 한계가 명확했습니다.
농장별로 재배 작물, 토양 상태, 작업 이력 등이 모두 다르기 때문에
일반적인 LLM 응답만으로는 사용자에게 실질적으로 도움이 되는 답변을 제공하기 어려웠습니다.
특히 농업 도메인은 정보의 정확도가 중요한 영역이기 때문에 잘못된 정보가 제공될 경우 실제 생산성에 영향을 줄 수 있다는 점도 고려해야 했습니다.
이러한 문제를 해결하기 위해 농촌진흥청의 작물별 재배 가이드와 내부 농장 데이터를 함께 활용할 수 있는 구조가 필요했고, 그 대안으로 RAG를 도입하게 되었습니다.
2. RAG란 무엇인가
그렇다면 RAG는 무엇일까요.
RAG(Retrieval-Augmented Generation)는 검색(Retrieval)과 생성(Generation)을 결합한 구조로, 외부 데이터를 기반으로 LLM이 보다 정확한 답변을 생성하도록 돕는 방식입니다.
LLM은 학습된 데이터 분포를 기반으로 다음 토큰을 확률적으로 생성하기 때문에, 사실 여부와 관계없이 그럴듯한 문장을 만들어내는 할루시네이션(hallucination) 문제가 발생할 수 있습니다.
RAG는 이러한 한계를 보완하기 위해, 외부 데이터를 벡터 형태로 저장한 뒤 사용자 질문과 유사한 문서를 검색하고, 이를 LLM의 입력 컨텍스트로 주입하여 답변을 생성하도록 합니다.
즉, LLM이 단순히 학습된 지식에 의존하는 것이 아니라
실제 데이터를 기반으로 응답을 생성하도록 만드는 구조입니다.
정리하면 RAG는 다음과 같은 한계를 보완하기 위해 사용할 수 있습니다.
- 할루시네이션 감소 : 검증된 데이터를 기반으로 답변을 생성하여 신뢰도 향상
- 최신성 확보 : 학습 이후의 최신 데이터를 반영할 수 있는 구조
- 보안 및 전문성 확보 : 사내 데이터 및 특정 도메인 데이터를 안전하게 활용 가능
3. RAG 구현 과정
3.1 기술 검토
RAG 구조를 도입하기로 결정한 이후, 가장 먼저 고민했던 부분은
어떤 기술 스택과 구조로 이를 구현할 것인가였습니다.
당시 요구사항은 다음과 같았습니다.
- 농업 도메인 데이터 기반 정확한 응답
- 사용자 농장 데이터를 반영한 개인화
- 빠른 응답 속도
- 향후 기능 확장을 고려한 구조
- 회사 참여 중인 GCP 스타트업 프로그램 크레딧 사용 가능 여부
이를 만족시키기 위해 다음과 같은 방향으로 기술을 검토했습니다.
기존 사용하던 AWS 인프라 대신 Google Cloud 기반 아키텍쳐를 구상해야 했고 다행히 기존 PoC에서 Gemini API 를 사용했던 경험이 있었기에 이 부분은 크게 어렵지 않았습니다. 다만 당시 회사에서는 이러한 구조를 다뤄본 사람이 없었고 따라서 최대한 빠른 시간 내에 인프라 내에서 해결 가능한 부분이 있는지를 우선적으로 검토했습니다.
pgvector 등 다양한 선택지가 있었으나 초기 MVP에서 가장 빠르고 정확성 있는 완성도를 구현하기에는 Google Vertex AI Search 가 가장 효과적일 것이라 판단해 벡터 DB로 활용하고자 했습니다.
그리고 AI 서버는 다음과 같은 역할을 수행해야 했습니다.
- 사용자 요청 처리
- RAG 검색 결과 결합
- LLM 호출 및 응답 생성
- Tool 선택 및 분기 처리
이를 위해 Python 기반의 FastAPI 와 LangChain 을 활용하여 AI 서버를 구성했습니다.
특히 단순한 RAG 구조가 아니라,
사용자 질의에 따라 RAG를 사용할지, 내부 API를 호출할지를 판단하는 Agent 구조를 도입하는 것이 목표였기에 LangGraph 등을 활용했고 성능 개선 과정에서 LangChain 1.0 버전이 새로 나왔고 이 참에 LangChain create_react_agent 방식으로 Agent 구조를 구축했습니다.
3.2 데이터 저장 구조
단순히 구현을 했다는 것을 넘어 데이터 저장 구조를 어떻게 처리할 지는 성능에 있어 굉장히 중요한 요소 중 하나입니다. 원본 자료를 GCP 버킷에 올리고 나면 Cloud Function을 활용하여 청킹과 임베딩 등 전처리 파이프라인을 구축하고자 했기 때문에 아래처럼 원본 데이터와 임베딩 데이터를 각각 분리해주었습니다.
원본 데이터는 농촌진흥청에서 제공하는 작물별 재배 자료와 농법 가이드 문서를 기반으로 구성했습니다.
해당 문서들은 PDF 형태로 정리한 뒤 Cloud Storage 버킷에 저장했습니다.
초기 버킷 구조는 아래와 같았으며 임베딩 후 벡터화된 데이터는 추후 성능 개선 시Firestore 로 옮긴 점을 제외 하고는 아래 구조를 유지하고자 했습니다.
farmit-rag-docs
├── raw-data
│ └── documents
└── processed-data
├── vectors
└── docstore
이렇게 분리한 이유는 원본 데이터와 검색용 데이터를 명확히 구분하기 위해서였습니다.
RAG에서는 검색 정확도뿐 아니라, 검색된 벡터가 실제 어떤 원문에서 나온 것인지 추적할 수 있어야 합니다. 따라서 임베딩 벡터와 원문 텍스트를 함께 관리할 수 있는 구조가 필요했습니다.
3.3 전처리 파이프라인 구축
전처리 파이프라인은 Cloud Storage에 PDF가 업로드되면 자동으로 실행되도록 구성했습니다. 흐름은 다음과 같습니다.
PDF 업로드
→ Cloud Run Function Trigger
→ PDF 텍스트 추출
→ 문서 정규화
→ Chunking
→ Metadata 부여
→ Embedding 생성
→ Vector 파일 저장
→ 원문 Docstore 저장
전처리 과정에서 가장 중요하게 본 부분은 chunking이었습니다. 문서 전체를 하나의 벡터로 변환하면 검색 단위가 너무 커져서 사용자의 질문과 정확히 맞는 부분을 찾기 어렵습니다. 반대로 너무 작게 나누면 문맥이 끊겨 LLM이 답변을 생성할 때 필요한 정보가 부족해질 수 있습니다.
따라서 문서를 페이지와 제목 정보를 기준으로 나누고, 각 chunk에 다음과 같은 메타데이터를 함께 부여했습니다.
source_path
source_file
category
crop
page_start
page_end
heading_path
chunk_id
이 메타데이터는 이후 검색 결과를 필터링하거나, 검색된 문서의 출처를 추적하는 데 활용했습니다.
3.4 Vector Search 인덱싱
전처리된 문서는 Vertex AI Vector Search에서 검색 가능한 형태로 인덱싱했습니다.
인덱싱 과정에서는 다음 요소를 맞춰야 했습니다.
- 임베딩 모델의 출력 차원
- 인덱스 차원 수
- 거리 측정 방식
- 인덱스 알고리즘
- 배포 리전
- Private Endpoint 설정
당시 사용한 임베딩 모델의 출력 차원에 맞춰 인덱스 차원을 설정했고, 유사도 기준은 cosine similarity를 사용했습니다.
또한 인덱스는 단순히 생성하는 것에서 끝나지 않고, 실제 FastAPI 서버에서 검색 요청을 보낼 수 있도록 Index Endpoint에 배포해야 했습니다.
이 과정에서 Vertex AI Vector Search는 일반적인 REST API처럼 바로 호출하는 구조가 아니라, Private Service Connect와 VPC 네트워크 설정이 함께 필요했습니다. 이 부분은 이후 트러블 슈팅에서 가장 많은 시간을 사용한 지점이기도 했습니다.
3.5 FastAPI 기반 AI 서버 구축
프론트엔드와 기존 Farmit 백엔드 외에 AI 기능만 담당하는 별도 서버를 FastAPI로 구축했습니다.
AI 서버의 역할은 다음과 같았습니다.
- 사용자 질문 수신
- Guardrail 검사
- RAG 검색
- Farmit Backend API 호출
- LLM 응답 생성
- SSE 기반 스트리밍 응답
- 추천 할 일 생성
- 일지 기반 기대효과 분석
- 태그 추천
API는 기능별로 버저닝을 하여 분리했습니다.
특히 챗봇은 사용자가 응답을 기다리는 시간이 길게 느껴질 수 있기 때문에 SSE 기반 스트리밍 방식으로 구현했습니다. 이를 통해 전체 응답이 완성될 때까지 기다리지 않고, 생성되는 응답을 순차적으로 사용자에게 보여줄 수 있도록 했습니다.
3.6 Agent 기반 Flow 설계
초기에는 LangGraph 기반으로 질문을 분류한 뒤, farmit, rag, both 중 하나의 경로로 라우팅하는 구조를 사용했습니다.
사용자 질문
→ normalize
→ route
→ farmit | rag | both
→ 응답 생성
이 구조는 구현이 단순하다는 장점이 있었지만, 실제 서비스 요구사항이 늘어나면서 한계가 명확했습니다.
예를 들어 사용자가 “이번 주 방울토마토 작업 기록을 보고 다음 주에 해야 할 일을 추천해줘”라고 질문하면, 단순 RAG 검색만으로는 부족합니다.
이 경우에는 다음 정보들이 함께 필요했습니다.
- 사용자 농장 정보
- 작물 정보
- 영농일지
- 완료된 작업
- 미완료 작업
- 날씨 정보
- 농법 가이드
즉, 단일 경로 라우팅이 아니라 여러 도구를 조합해서 판단하는 구조가 필요했습니다.
그래서 이후에는 LangChain의 Tool 기반 Agent 구조로 전환했습니다.
RAG 검색, Farmit 데이터 조회, 날짜 처리, 날씨 조회 등을 각각 Tool로 분리하고, Agent가 질문 의도에 따라 필요한 Tool을 선택하도록 구성했습니다.
이 구조를 통해 단순한 문서 검색 챗봇이 아니라, Farmit의 서비스 데이터와 외부 농업 데이터를 함께 활용하는 AI 기능으로 확장할 수 있었습니다.
4. 주요 기능 구현
4.1 RAG 기반 챗봇
챗봇은 사용자가 농장 정보나 농법에 대해 질문하면, Agent가 질문을 분석한 뒤 필요한 정보를 조회하고 응답하는 방식으로 구현했습니다.
질문 유형은 크게 두 가지로 나눴습니다.
1. 농법/작물 정보 질문
→ RAG 검색 사용
2. 사용자 농장/작업 이력 질문
→ Farmit Backend API 사용
예를 들어 “토마토 잎이 노랗게 변했을 때 어떻게 해야 하나요?”와 같은 질문은 RAG 검색을 통해 농법 가이드 기반으로 답변하도록 했습니다.
반면 “내 농장에서 오늘 해야 할 일 알려줘”와 같은 질문은 사용자 농장 데이터와 작업 이력을 조회해야 하므로 Farmit Backend API를 호출하도록 했습니다.
이렇게 질문 유형에 따라 처리 방식을 분리하면서도, 최종 사용자 입장에서는 하나의 챗봇 안에서 자연스럽게 응답을 받을 수 있도록 구성했습니다.
4.2 추천 할 일 생성
Farmit의 핵심 기능 중 하나는 농장 기반 추천 할 일이었습니다. 추천 할 일 생성에는 단순히 농법 가이드만 필요한 것이 아니라, 사용자별 현재 상태가 함께 필요했습니다.
입력 데이터는 다음과 같았습니다.
- 사용자 농장 정보
- 재배 작물
- 최근 영농일지
- 완료된 작업
- 미완료 작업
- 날씨 정보
- RAG 기반 농법 가이드
AI 서버는 이 데이터를 조합하여 사용자가 오늘 또는 이번 주에 수행하면 좋을 작업을 추천했습니다. 이 기능에서 중요했던 점은 “그럴듯한 추천”이 아니라 근거 있는 추천이었습니다. 따라서 추천 결과에는 단순 작업명만 포함하지 않고, 왜 이 작업이 필요한지에 대한 근거와 기대효과를 함께 제공하도록 설계했습니다.
4.3 영농일지 기반 기대효과 생성
영농일지 작성 과정에서는 사용자가 기록한 작업을 기반으로 특이사항과 기대효과를 생성하는 기능을 구현했습니다.
예를 들어 사용자가 방제 작업, 관수 작업, 생육 관찰 내용을 기록하면 AI가 이를 바탕으로 다음과 같은 내용을 생성합니다.
- 이번 작업의 의미
- 작물 생육에 미칠 수 있는 영향
- 이후 관찰해야 할 포인트
- 다음 작업 제안
이 기능은 단순히 기록을 자동 요약하는 것이 아니라, 사용자가 작성한 영농일지를 다시 활용 가능한 데이터로 바꾸는 역할을 했습니다.
Farmit이 단순 기록 앱이 아니라 농장 운영을 돕는 서비스가 되기 위해서는, 사용자가 입력한 데이터가 다시 추천과 분석으로 이어지는 구조가 필요했습니다.
4.4 태그 추천
커뮤니티 게시글이나 영농 기록에 적합한 태그를 자동 추천하는 기능도 구현했습니다. 특히 커뮤니티 기능도 있었기에 사용자 입력 글을 바탕으로 맞춤 태그를 제시해주는 것만으로도 사용자 참여도를 높일 수 있었기에 필수 기능은 아니지만 구현 하고자 했습니다. 또한 이후 특정 작물, 증상, 작업 유형별로 데이터를 분류하거나 검색할 수 있는 기반이 되기 때문에 Farmit의 데이터 활용성을 높이는 기능으로 보았습니다.
5. 성능 개선 및 트러블 슈팅
5.1 GCP Client 지연 문제
가장 큰 문제는 응답 속도였습니다.
초기 구조에서는 /chat/agent/stream API가 호출될 때마다 다음 작업이 반복되었습니다.
- Gemini Model Client 초기화
- Vertex Search Index Endpoint Client 초기화
- 원본 데이터 캐싱
- RAG 검색 준비
이 과정에서 사용자 요청마다 GCP Client 연결이 새로 발생했고, 특히 Vertex Search와의 gRPC 통신에서 연결 지연이 크게 발생했습니다.
초기 응답 지연 시간은 약 120~130초 수준까지 발생했습니다.
사용자 입장에서는 사실상 서비스 사용이 어려운 수준이었습니다.
이를 해결하기 위해 GCP Client를 요청마다 생성하지 않고, 서버 프로세스 시작 시점에 초기화하는 방식으로 변경했습니다.
적용한 개선은 다음과 같습니다
- Singleton Client 패턴 적용
- 서버 시작 시 GCP Client 선초기화
- Keep-alive 설정
- 90초 주기 warming 호출
- JWT 및 연결 정보 재사용
그 결과 응답 지연 시간을 약 120초에서 2초 내외로 줄일 수 있었습니다.
5.2 원본 데이터 캐싱 구조 개선
초기에는 임베딩 결과와 연결된 원문 데이터를 서버 메모리에 캐싱하는 방식으로 구현했습니다. 하지만 이 방식은 서버 시작 시점에 원본 데이터를 다운로드해야 했고, 데이터가 늘어날수록 초기화 시간이 길어지는 문제가 있었습니다. 또한 Cloud Run 환경에서는 인스턴스가 언제든 새로 뜰 수 있기 때문에, 매번 캐시를 새로 구성하는 구조는 안정적이지 않았습니다.
이를 개선하기 위해 전처리 파이프라인을 수정했습니다.
기존:
GCS의 원문 데이터를 서버 메모리에 캐싱
개선:
chunk 원문은 Firestore에 저장
검색 결과 ID를 기준으로 Firestore에서 원문 조회
즉, Vector Search에는 검색용 벡터와 ID를 저장하고, 실제 원문 텍스트는 Firestore에서 조회하도록 분리했습니다.
이렇게 변경하면서 서버 초기화 시점의 캐싱 부담을 줄이고, 검색 결과와 원문 조회를 더 안정적으로 처리할 수 있었습니다.
5.3 Private Service Connect 설정 문제
Vertex AI Vector Search Index Endpoint를 private endpoint로 배포하면서 네트워크 관련 문제도 겪었습니다.
로컬 환경에서 엔드포인트를 호출했을 때 DNS resolution failed 에러가 발생했습니다.
처음에는 단순한 주소 문제라고 생각했지만, 실제 원인은 private endpoint가 VPC 내부에서만 접근 가능한 구조였기 때문이었습니다.
이후 GCE 인스턴스에서 다시 테스트했지만 동일한 문제가 발생했고, 추가로 확인한 결과 Private Service Connect 설정과 서비스 연결 정책이 제대로 구성되지 않은 것이 원인이었습니다.
해결 과정은 다음과 같았습니다.
- Vertex AI Index Endpoint를 private endpoint로 배포
- VPC 네트워크 설정
- Private Service Connect 연결 정책 생성
- GCE 서비스 계정 권한 부여
- psc_network 파라미터 명시
- Private Google Access 활성화
- Cloud DNS 설정 확인
이외 부가적으로 설정한 인프라 환경은 여러 가지 있었으나 저런 개선 방안을 도입 했더니 연결 과정에서 발생하는 에러 발생 확률이 95% 이상 감소 했습니다.
이 과정은 단순히 코드를 작성하는 것보다 GCP 네트워크 구조를 이해하는 시간이 더 많이 필요했습니다. 이 때를 기점으로 인프라 설정의 중요성을 크게 깨닫기도 했습니다.
5.4 Agent 구조 개선
초기 LangGraph 기반 구조는 farmit, rag, both 중 하나로 라우팅하는 방식이었습니다.
하지만 서비스 요구사항이 늘어나면서 단순 라우터 방식은 한계가 있었습니다. 문제는 다음과 같았습니다.
- 하나의 flow가 끝나면 종료됨
- 여러 Tool을 반복적으로 조합하기 어려움
- 날짜 파싱, 농장 데이터 조회, RAG 검색을 함께 처리하기 어려움
- Tool 선택 실패 시 재시도 구조가 약함
이를 개선하기 위해 LangChain v1.0 기반의 create_agent 구조로 전환했습니다.
각 기능은 Tool로 분리했습니다.
- RAG 검색 Tool
- Farmit 데이터 조회 Tool
- 날짜 처리 Tool
- 날씨 조회 Tool
- 추천 할 일 생성 Tool
- 태그 생성 Tool
이후 Agent가 사용자 질문을 보고 필요한 Tool을 선택하고, Tool 실행 결과를 바탕으로 다음 행동을 결정하도록 구성했습니다.
이 구조를 통해 기존의 하드코딩된 라우팅 방식보다 유연하게 복합 질문을 처리할 수 있었습니다. 다만 이 과정에서 다양한 케이스가 생기게 되었고 프롬프트 라우팅 기법을 통해 최대한 근접한 경우로 라우팅 되도록 개선했습니다.
5.5 모델 선택 최적화
모든 기능에 동일한 모델을 사용하는 것은 비용과 성능 측면에서 비효율적이었습니다. 실제 프로덕션 운영 시 토큰 수에 따른 비용 또한 무시 못할 존재이기 때문에 이를 개선할 필요가 있었습니다.
그래서 기능의 중요도와 응답 품질 요구사항에 따라 모델을 분리했습니다. 간단히 예시를 들자면 아래와 같이 분리하고자 했습니다.
가드레일 및 분기: Gemini 2.5 Flash Lite
Chat: Gemini 2.5 Flash
추천 할 일 생성: Gemini 2.5 Pro
가벼운 검증이나 분류 작업은 상대적으로 비용이 낮은 모델을 사용하고, 추천 할 일처럼 더 높은 품질이 필요한 기능에는 더 성능이 좋은 모델을 사용했습니다.
이렇게 모델을 분리하면서 전체 비용을 줄이면서도, 주요 기능의 응답 품질은 유지할 수 있었습니다.
5.6 GuardRail 및 Late Limit
AI 기능을 실제 서비스에 넣기 위해서는 정상적인 질문뿐 아니라 비정상적인 입력도 고려해야 했습니다.
특히 챗봇은 사용자가 자유롭게 입력할 수 있는 영역이기 때문에 다음과 같은 위험이 있었습니다.
- 프롬프트 인젝션
- 서비스와 무관한 질문
- 욕설 및 비속어
- 개인정보 포함 입력
- 과도한 API 호출
이를 방지하기 위해 Guardrail과 Rate Limit을 함께 적용했습니다. Guardrail은 1차 키워드 기반 필터링과 LLM 기반 정밀 검증을 조합했습니다.
1차: 키워드 기반 필터링
2차: LLM 기반 토픽 분류 / 위험도 점수화 / PII 감지
또한 Rate Limiter를 적용해 사용자의 과도한 호출을 제한하고, 비용 폭증을 방지할 수 있도록 했습니다.
6. 모니터링
AI 기능은 일반 API보다 디버깅이 어렵습니다. 같은 입력처럼 보여도 모델 응답이 달라질 수 있고, Tool 선택 과정이나 RAG 검색 결과에 따라 최종 응답 품질이 크게 달라집니다.
이를 추적하기 위해 LangSmith를 연동했습니다. LangSmith를 통해 확인하고자 했던 항목은 다음과 같습니다.
- 사용자 질문
- 선택된 Tool
- Tool 실행 결과
- LLM 입력 Prompt
- LLM 응답
- 응답 시간
- 에러 발생 지점
특히 Agent 구조에서는 “왜 이 Tool을 선택했는가”를 추적하는 것이 중요했습니다. 단순히 최종 응답만 보면 문제가 LLM 응답 품질 때문인지, RAG 검색 결과 때문인지, Tool 선택이 잘못된 것인지 구분하기 어렵습니다.
LangSmith를 통해 각 실행 단계를 추적하면서 AI 기능의 품질을 개선할 수 있는 기반을 마련했습니다.
7. 결과 및 회고
이번 작업을 통해 단순히 LLM API를 호출하는 기능이 아니라, 실제 서비스에서 동작 가능한 AI 아키텍처를 구성할 수 있었습니다.
최종적으로 구현한 내용은 다음과 같습니다.
- GCP 기반 RAG 데이터 파이프라인 구축
- Vertex AI Vector Search 기반 검색 구조 구현
- FastAPI 기반 AI 서버 구축
- SSE 기반 챗봇 스트리밍 응답 구현
- LangChain Agent 기반 Tool 선택 구조 도입
- Farmit Backend API와 RAG 검색 결합
- 추천 할 일 / 일지 기대효과 / 태그 추천 기능 구현
- Guardrail 및 Rate Limit 적용
- LangSmith 기반 모니터링 구성
적다 보니 나름 많이 했구나 하는 뿌듯함도 있었지만 이 기능을 맡을 당시에는 정말 많은 고민이 있었습니다. 프론트엔드 개발을 더 깊게 파야 나중에 커리어적으로 유리하지 않을까와, 내가 잘 할 수 있을까라는 불안감이 함께 있었습니다.
그렇지만 팀원들과 함께 고민하고 팀원들이 제게 많은 도움을 주시려 했던 것들 덕분에 꽤 괜찮은 서비스로 발전할 수 있었습니다.
이를 기점으로 특정 기술 스택이 아닌 Product 에 대해 고민하며 커리어적으로 많은 생각을 하게 됐던 것 같습니다.
물론 지금 다시 보면 아쉬운 부분도 있긴 하지만 하나부터 열까지 직접 해보면서 성장했던 경험은 정말 잊지 못할 것 같고 앞으로 업무를 하면서 큰 자신감으로 작용하게 되었습니다.
종종 AI 분야에서 공부 했던 것들, 해온 것들을 틈틈이 올려나갈 계획입니다. 감사합니다.